Go back to Blogs
Introducing Self supervised Learning: The future of deep learning
ℹ️
- We sometimes use affiliate links in our content. This means that if you click on a link and make a purchase, we may receive a small commission at no extra cost to you. This helps us keep creating valuable content for you!
Contents
- Context
- Challenges
- Solution: Self-Supervised Learning
- Pretext Task: The Heart of SSL
- Advantages of SSL
- Applications
- Challenges and Future Directions
- Conclusions
- References
Context
The rise of deep learning has demonstrated the power of complex models to learn intricate patterns from data. However, these models, particularly in areas like computer vision and natural language processing, often require vast amounts of labeled data for training. This labeled data (e.g., images with object annotations, text with sentiment labels) is expensive and time-consuming to acquire. Human annotation is a bottleneck, especially when dealing with massive datasets or specialized domains. Furthermore, in some scenarios, obtaining labels might be practically impossible (e.g., in medical imaging where expert annotations are scarce).
Challenges
The core challenge is the data bottleneck caused by the reliance on labeled data. This bottleneck hinders the development and deployment of powerful deep learning models, especially in situations where labeled data is scarce or expensive. Specifically, the problem manifests in several ways:
- High cost of annotation: Labeling data requires human effort, which translates to significant financial cost and time investment.
- Limited scalability: The need for labeled data restricts the scale at which deep learning models can be applied. Many real-world problems involve massive datasets that are simply too large to label manually.
- Bias and inconsistency: Human annotation can be subjective, leading to biases and inconsistencies in the labeled data, which can negatively impact model performance.
- Domain adaptation challenges: Models trained on labeled data from one domain often struggle to generalize to other domains where labeled data is not available.
Solution: Self-Supervised Learning
Self-supervised learning offers a solution to the data bottleneck by learning from unlabeled data. The key idea is to define pretext tasks that leverage the inherent structure of the data itself to create “pseudo-labels” or learning signals. These pretext tasks are designed such that solving them requires the model to learn meaningful representations of the data, even without explicit human annotations.
Here’s how SSL addresses the problem:
- Eliminates the need for manual labels: By generating pseudo-labels from the data itself, SSL removes the reliance on human annotation, significantly reducing the cost and effort of data preparation.
- Enables learning from massive unlabeled datasets: SSL can leverage the abundance of unlabeled data available in many domains, allowing models to learn richer and more generalizable representations.
- Reduces bias and improves consistency: Since pseudo-labels are generated automatically, they are less susceptible to human bias and inconsistencies.
- Facilitates domain adaptation: Models trained with SSL on unlabeled data can often be fine-tuned with a small amount of labeled data from the target domain, improving domain adaptation performance.
In essence, SSL shifts the focus from learning from labeled data to learning from the data’s inherent structure. By defining clever pretext tasks, SSL unlocks the potential of massive unlabeled datasets, paving the way for more powerful and versatile AI systems. It’s a paradigm shift that addresses the data bottleneck and makes deep learning more accessible and applicable to a wider range of real-world problems.
Pretext Tasks: The Heart of SSL
The choice of pretext task is crucial for the success of SSL. It should be designed to capture essential aspects of the data distribution and encourage the model to learn features that are relevant for downstream applications. Here are some common pretext tasks:
Image based
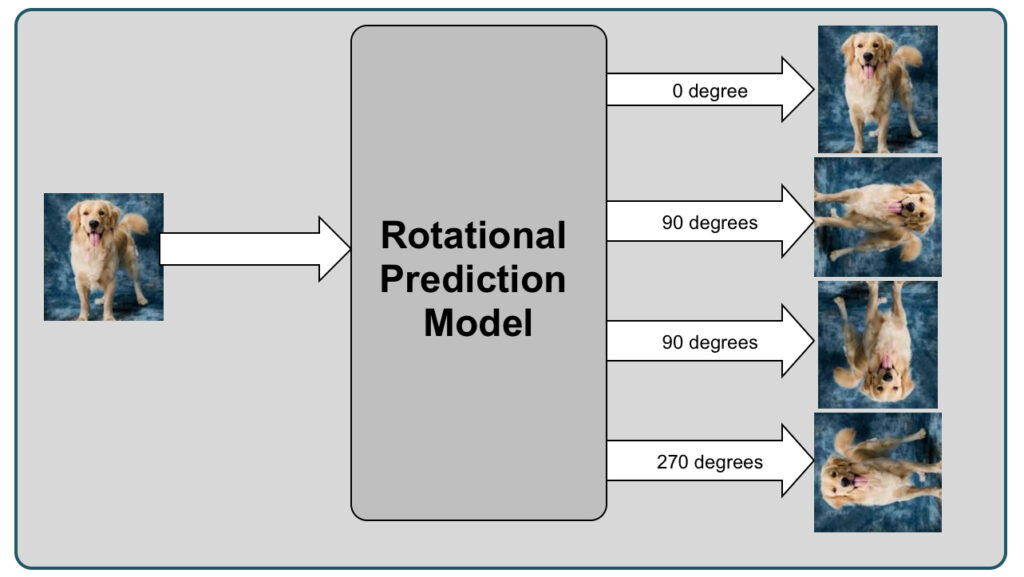
Rotation Prediction
An image is rotated by a random angle (e.g., 0, 90, 180, 270 degrees), and the model is tasked with predicting the orientation of the image or rotation angle. This forces the model to understand the spatial structure of the image.
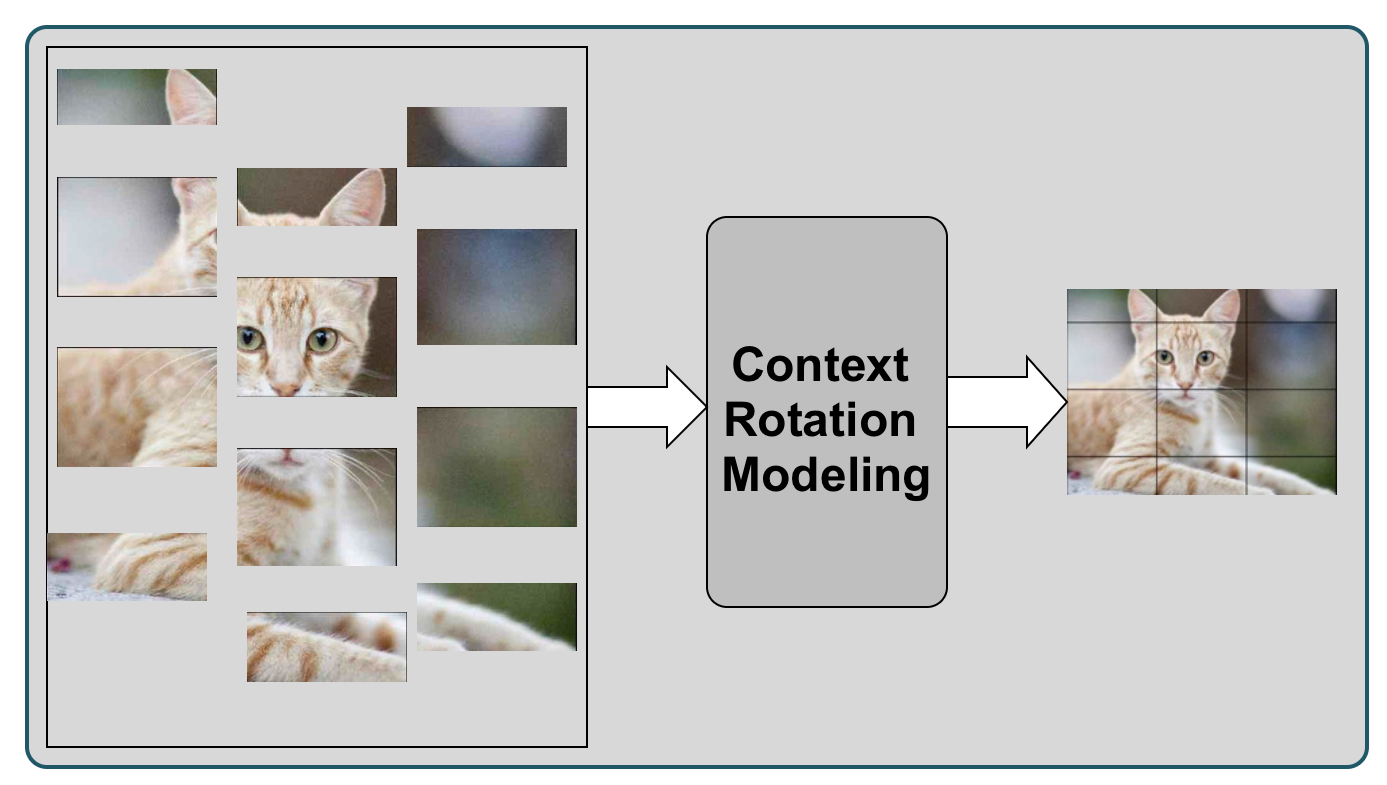
Context Restoration (Jigsaw Puzzles)
An image is divided into patches, shuffled, and the model must reconstruct a complete image from scrambled pieces, essentially “restoring” the original context by learning the spatial relationships between different parts of an image, similar to how a person solves a jigsaw puzzle by piecing together the fragments to create a whole picture. This encourages the model to learn about object boundaries and spatial relationships.
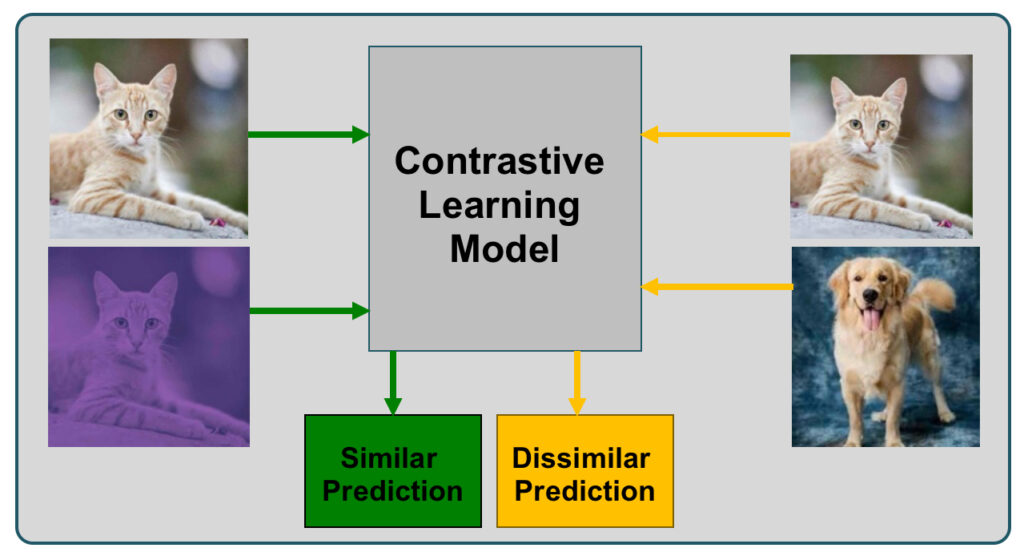
Contrastive Learning
Two augmented versions of the same image are created (e.g., by applying different random crops, color jittering, or Gaussian blur). The model is trained to maximize the similarity between the representations of these two augmented views while minimizing the similarity between representations of different images. Popular methods include SimCLR, MoCo, and BYOL. Check out our blog on Python implementation of Contrastive Learning using SimSCR method.
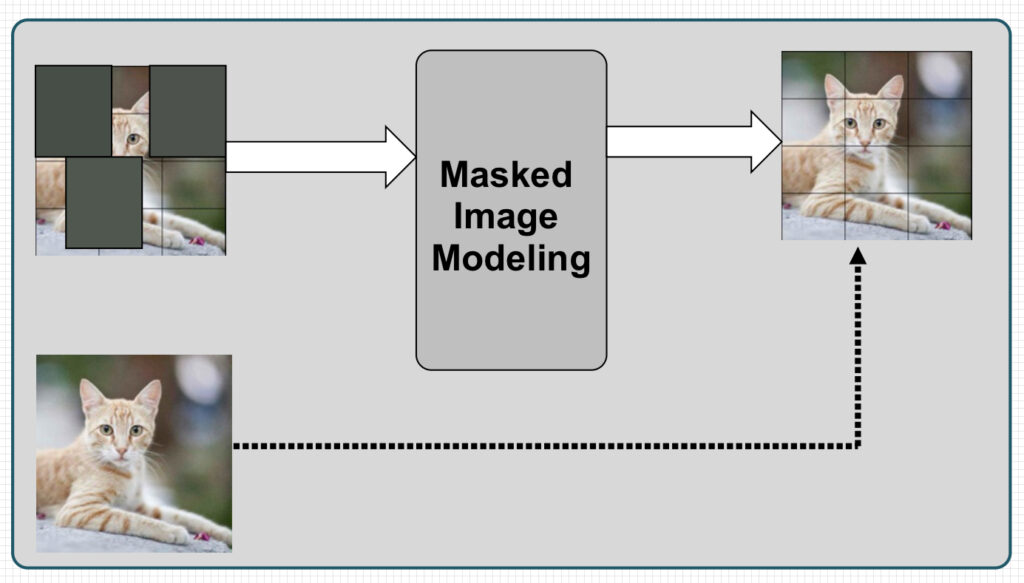
Masked Image Modeling
Similar to masked language modeling (discussed below), parts of an image are masked, and the model is trained to reconstruct the missing content. BEiT is a prominent example.
Text based
- Masked Language Modeling (MLM): A fraction of words in a sentence is masked, and the model is trained to predict the masked words. BERT and its variants are based on this approach.
- Next Sentence Prediction (NSP): Given two sentences, the model predicts whether the second sentence follows the first one. This task was originally used in BERT but has been largely replaced by other techniques.
- Sentence Ordering: A set of sentences is shuffled, and the model is trained to restore the original order.
Video based
Temporal Ordering
A sequence of frames from a video is shuffled, and the model must predict the correct temporal order. The core idea is to train a model to understand the order of events in a video by predicting the correct sequence of shuffled frames.
How it Works
- Video Segmentation: A video is divided into a sequence of frames or short clips.
- Shuffling: The order of these frames/clips is randomly shuffled.
- Model Training: A model is trained to predict the correct temporal order of the shuffled frames/clips. The input to the model is the shuffled sequence, and the output is the predicted order.
- Self-Supervision: The “self-supervised” aspect comes from the fact that the correct order is naturally present in the video itself. No manual labeling is required. The video provides its own “ground truth” for the task.
Example (Conceptual)
Imagine a short video of someone walking across a room. You might have frames like:
- Frame 1: Person at the door
- Frame 2: Person halfway across the room
- Frame 3: Person reaching the other side
Temporal ordering is a powerful self-supervised learning technique for video representation learning. It exploits the temporal information present in videos to learn features that are useful for understanding and analyzing video content.
Video Prediction
The model is trained to predict future frames given a sequence of past frames. It’s a challenging task that requires the model to understand not only the spatial content of the video but also the temporal dynamics and how objects move and interact over time.
How it Works
- Input Sequence: The model is given a sequence of past frames from a video as input.
- Prediction: The model is trained to predict one or more future frames.
- Self-Supervision: The “ground truth” for the prediction is the actual future frames from the video. No manual labels are needed. The video itself provides the supervision signal.
Video prediction is an active area of research in self-supervised learning. It’s a challenging but promising task that can lead to a deeper understanding of video content and dynamics.
Advantages of SSL
Reduced Reliance on Labeled Data and Cost
- Significant Cost Reduction: Manual annotation is expensive and time-consuming. SSL drastically reduces or eliminates this cost, making it feasible to train models on much larger datasets.
- Scalability: SSL enables the use of massive amounts of unlabeled data, which are often readily available (e.g., images, videos, text on the internet). This scalability is crucial for tackling complex problems.
- Faster Iteration: Without the bottleneck of labeling, researchers and practitioners can iterate more quickly on model development and experimentation.
Improved Generalization and Robustness
- Robust Representations: SSL encourages models to learn more robust and invariant features. By training on diverse augmentations or pretext tasks, the models become less sensitive to superficial variations in the input data.
- Better Generalization: Models trained with SSL often generalize better to unseen data compared to supervised models trained on limited labeled data. They are less prone to overfitting to the specific characteristics of the labeled training set.
- Noise Tolerance: SSL can make models more resilient to noisy or incomplete data, as they are not solely reliant on potentially flawed labels.
Potential for Discovering New Patterns and Insights
- Uncovering Hidden Structures: SSL models can uncover hidden structures and relationships in the data that might be missed by supervised methods, which are guided by predefined labels. This can lead to new discoveries and a deeper understanding of the data.
- Feature Discovery: SSL can automatically learn relevant features from the data, reducing the need for manual feature engineering. This can be especially valuable in domains where it’s difficult to define meaningful features a priori.
Addressing Data Bias
- Mitigating Label Bias: Supervised learning can be susceptible to biases present in the labeled data. SSL, by learning from the data itself, can potentially mitigate some of these biases.
- Discovering Unseen Biases: SSL models might even reveal previously unknown biases or patterns in the data that were not apparent in the limited labeled subset.
Applications
Computer Vision
- Object Detection: SSL can improve object detection by learning better feature representations that are invariant to variations in pose, lighting, and scale. This can lead to more accurate and robust object detectors, especially when labeled data is limited.
- Image Segmentation: SSL can be used to learn representations that capture the semantic structure of images, leading to improved image segmentation. This is crucial for applications like medical image analysis and autonomous driving.
- Image Classification: SSL can significantly boost image classification accuracy, particularly in few-shot learning scenarios where only a small number of labeled examples are available.
- Generative Modeling: SSL can be used to learn better latent representations for generative models, leading to more realistic and diverse image generation.
Natural Language Processing (NLP)
- Sentence Embeddings: SSL can be used to learn high-quality sentence embeddings that capture the semantic meaning of sentences. These embeddings are crucial for various NLP tasks, including text classification, sentiment analysis, and machine translation.
- Machine Translation: SSL can improve machine translation by learning better representations of words and sentences, leading to more accurate and fluent translations.
- Language Modeling: SSL can be used to train language models that can predict the next word in a sequence, which is essential for tasks like text generation and question answering.
Speech Processing
- Speaker Identification: SSL can be used to learn representations that capture the unique characteristics of a speaker’s voice, leading to more accurate speaker identification.
- Speech Recognition: SSL can improve speech recognition by learning better representations of speech sounds, making the system more robust to noise and variations in accent.
- Speech Synthesis: SSL can be used to learn better representations of speech, leading to more natural and expressive speech synthesis.
SSL is a powerful technique with broad applicability across various domains. Its ability to learn from unlabeled data makes it particularly valuable in situations where labeled data is scarce or expensive to obtain. As research in SSL continues to advance, we can expect to see even more innovative applications emerge in the future.
Challenges and Future Directions
Pretext Task Design
- Finding Optimal Pretext Tasks: Designing effective pretext tasks that capture the relevant semantic information for downstream applications is a major challenge. A poorly chosen pretext task might lead to representations that are not useful for the target task.
- Task Complexity: Pretext tasks need to be challenging enough to force the model to learn meaningful features but not so difficult that the model struggles to learn anything. Balancing complexity is crucial.
- Generalization Gap: Representations learned from one pretext task might not generalize well to other tasks. Developing pretext tasks that lead to more generalizable representations is an open problem.
Evaluation Metrics
- Lack of Universal Metrics: There is no single, universally accepted metric for evaluating the quality of learned representations in the absence of labels.
- Downstream Task Dependence: Linear evaluation on downstream tasks is the most common approach, but it can be computationally expensive and might not always be the best indicator of representation quality for all possible downstream tasks.
Theoretical Understanding
- Why SSL Works: A deeper theoretical understanding of why SSL works is still lacking. What principles underlie the success of different pretext tasks and loss functions?
- Sample Complexity: How much unlabeled data is needed to learn good representations? Can we characterize the sample complexity of SSL methods?
Scalability and Efficiency
- Computational Resources: Training large SSL models on massive datasets can require significant computational resources. Developing more efficient training methods is crucial.
- Memory Management: Handling large datasets and models efficiently in memory is a challenge.
- Distributed Training: Scaling SSL training to multiple GPUs or machines is essential for tackling very large datasets.
Future Directions
- Developing more powerful and generalizable pretext tasks.
- Creating better evaluation metrics for SSL representations.
- Gaining a deeper theoretical understanding of SSL.
- Bridging the gap between SSL and supervised learning.
By addressing these challenges and pursuing these future directions, the field of self-supervised learning can continue to advance and unlock its full potential for building more intelligent and adaptable AI systems.
Conclusions
Despite the inherent challenges, Self-Supervised Learning (SSL) stands as a rapidly evolving and immensely promising field with transformative potential. While open questions remain regarding optimal pretext task design, comprehensive evaluation metrics, and a complete theoretical understanding, the pace of progress is remarkable. Ongoing research is actively addressing these challenges, leading to increasingly innovative pretext tasks, refined learning paradigms, and a deeper appreciation of the underlying principles governing SSL. As we continue to explore the vast landscape of unlabeled data, we can anticipate a future where SSL plays a pivotal role in unlocking the full power of artificial intelligence. This progress will not only lead to more robust and generalizable AI models but also pave the way for tackling increasingly complex and data-scarce real-world problems. Ultimately, the continued development and refinement of SSL methodologies will be instrumental in building more adaptable, insightful, and truly intelligent AI systems capable of learning and reasoning with minimal human intervention.