Go back to Blogs
A Practical Guide to BYOL: Non Contrastive SSL
ℹ️
- We sometimes use affiliate links in our content. This means that if you click on a link and make a purchase, we may receive a small commission at no extra cost to you. This helps us keep creating valuable content for you!
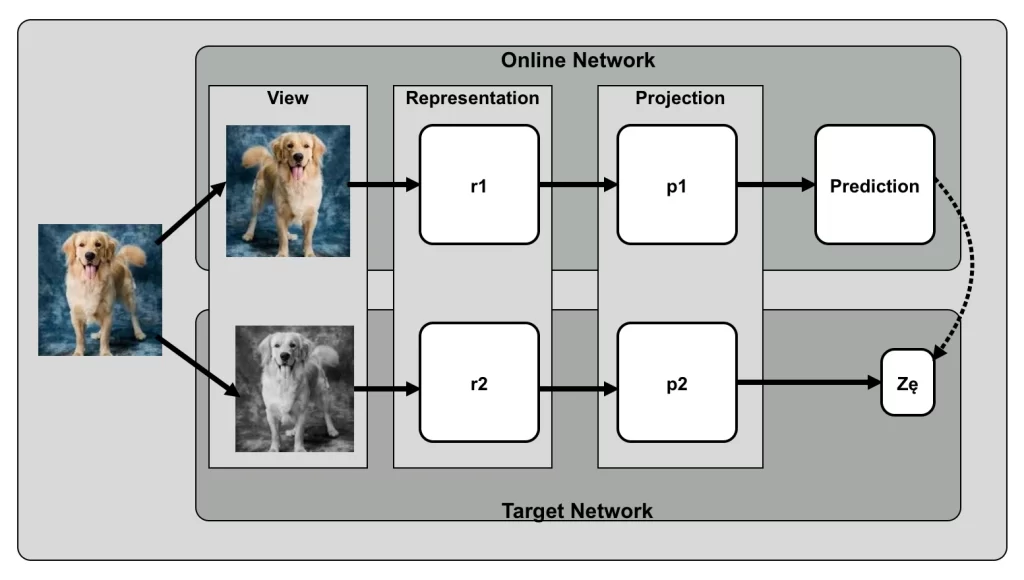
Table of Contents
- Introduction
- The Problem with Traditional SSL and the Rise of BYOL
- Core Mechanism of BYOL: Bootstrapping Your Own Latent Representations
- Why BYOL Works Without Negative Sampling
- Advantages of BYOL
- Practical Considerations and Implementation Details
- Testing and Evaluating Model Performance
- Conclusion
- References
Introduction
In our previous blog, we have introduced the concept of the Self-supervised learning model, which has emerged as a transformative paradigm in the field of machine learning, bridging the gap between unsupervised and supervised learning. We also delved deep into implementation of the Contrastive learning SSL model in Python. In this article, we will introduce a new SSL technique, Bootstrap Your Own Latent (BYOL), exploring its core principles, advantages and implementation in Python. BYOL has emerged as a powerful approach, offering a unique perspective on representation learning.
The Problem with Traditional SSL and the Rise of BYOL
Traditional SSL methods often rely on negative sampling, where the model learns to discriminate between different views of the same image and views of different images (positive and negative pairs of the images). This process can be computationally expensive and sensitive to the choice of negative samples. BYOL, introduced by Grill et al. in 2020, challenged this paradigm by demonstrating that high-quality representations can be learned without explicit negative sampling.
Core Mechanism of BYOL: Bootstrapping Your Own Latent Representations
At its heart, BYOL employs a bootstrap mechanism that relies on two neural networks, referred to as online and target networks, that interact and learn from each other. Here’s a breakdown of the key components:
- Two Networks: BYOL utilizes two neural networks: an online network and a target network. Both networks have the same architecture but different weights.
- Data Augmentations: Two different augmentations are applied to the same input image, creating two distinct views.
- Online Network Processing: One augmented view is passed through the online network, producing a representation. This representation is then passed through a predictor network (a small MLP) to generate a prediction.
- Target Network Processing: The other augmented view is passed through the target network, producing a target representation.
- Mean Squared Error Loss: The prediction from the online network is compared to the target representation using a mean squared error (MSE) loss.
- Exponential Moving Average (EMA): The target network’s weights are updated using an exponential moving average (EMA) of the online network’s weights. This ensures that the target network is a slowly evolving version of the online network.
Why BYOL Works Without Negative Sampling
BYOL avoids collapse, where the model outputs the same representation for all inputs, through the combination of the predictor network and the EMA update.
- Predictor Network: The predictor network introduces asymmetry, preventing the online network from simply copying the target network’s output. It forces the online network to learn meaningful features that can be used to predict the target representation.
- EMA Update: The EMA update provides a stable and slowly evolving target, preventing the online network from overfitting to the current batch of data. This allows the model to learn robust and generalizable representations.
Advantages of BYOL
- Simplified Training: BYOL eliminates the need for negative sampling, simplifying the training process and reducing computational costs.
- Robustness: BYOL has demonstrated robustness to various data augmentations and hyperparameters.
- Performance: BYOL achieves state-of-the-art performance on various downstream tasks, such as image classification and object detection.
- Reduced Batch Size Dependency: BYOL can work well with smaller batch sizes than methods relying on negative sampling.
Practical Considerations and Implementation Details
When implementing BYOL, several practical considerations should be taken into account:
- Data Augmentations: The choice of data augmentations is crucial for BYOL’s performance. Common augmentations include random cropping, color jittering, Gaussian blur, and grayscale conversion.
- Predictor Network Architecture: The predictor network typically consists of a small MLP with one or two hidden layers.
- EMA Decay Rate: The EMA decay rate controls the speed at which the target network’s weights are updated. A higher decay rate results in a slower update.
- Batch Size and Learning Rate: These hyperparameters should be tuned based on the specific dataset and network architecture.
Base class for self-supervised learning tasks
This class acts as a foundational module for creating tasks in the self-supervised learning paradigm (this is the same base class used in the implementation of contrastive learning model). It is designed to provide structure for implementing specific self-supervised tasks with customizable components such as loss functions and data transformations. Derived subclasses are expected to implement the loss function and the transformation logic as required.
class SelfSupervisedTask(nn.Module):
def __init__(self, model):
super().__init__()
self.model = model.to(device) # Move model to device
def forward(self, x):
"""forward function """
return self.model(x)
def loss(self, x, y):
""" Loss function must be implemented by subclasses """
raise NotImplementedError(
"Loss function must be implemented by subclasses")
def transform(self, image):
""" Transform function must be implemented by subclasses """
raise NotImplementedError(
"Transform function must be implemented by subclasses")
Load data
Loads and preprocesses the CIFAR-10 training dataset, applying a series of data augmentation and normalization techniques. The function performs random resizing and cropping, random horizontal flipping, color jittering, and normalization based on the pre-computed dataset statistics. Finally, it creates a DataLoader object with shuffled batches of a specified size.
def load_data(batch_size=256, num_workers=10):
try:
transform_train = transforms.Compose([
transforms.RandomResizedCrop(32),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.4, contrast=0.4, saturation=0.4, hue=0.1),
transforms.ToTensor(),
transforms.Normalize(CIFAR10_MEAN, CIFAR10_STD)
])
train_dataset = torchvision.datasets.CIFAR10(
root='./data', train=True, download=True, transform=transform_train
)
train_loader = torch.utils.data.DataLoader(
train_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers
)
return train_loader
except Exception as e:
logger.error(f"Error in load_data: {e}")
BYOL Algorithm
This class is designed for self-supervised learning tasks using the BYOL framework. It utilizes an online encoder, a target encoder, and a predictor network for self-supervised representation learning. The target encoder is updated through an exponential moving average (EMA) of the online encoder’s parameters. The BYOL approach does not require negative samples or contrastive learning, focusing instead on learning representations through alignment of predictions and targets.
class BYOL(SelfSupervisedTask):
def __init__(self, base_model, feature_extractor, feature_size, tau=0.996):
super().__init__(base_model)
self.online_encoder = nn.Sequential(
feature_extractor,
nn.Flatten(), # Flatten the output from the feature extractor
nn.Linear(feature_size, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Linear(256, 256),
)
self.target_encoder = None # Will be initialized as a copy of online_encoder
self.predictor = nn.Sequential(
nn.Linear(256, 256),
nn.BatchNorm1d(256),
nn.ReLU(),
nn.Linear(256, 256)
)
self.tau = tau
# Initialize target network
self._init_target_network()
def _init_target_network(self):
"""
Initializes the target network as a copy of the online network.
"""
self.target_encoder = copy.deepcopy(self.online_encoder)
for param in self.target_encoder.parameters():
param.requires_grad = False
def forward(self, x1, x2):
"""Forward pass for BYOL"""
z1 = self.online_encoder(x1) # Projection head for online network
z2 = self.online_encoder(x2)
p1 = self.predictor(z1) # Predict online view 1
p2 = self.predictor(z2) # Predict online view 2
with torch.no_grad():
t1 = self.target_encoder(x1) # Target encoder for view 1
t2 = self.target_encoder(x2) # Target encoder for view 2
return p1, p2, t1.detach(), t2.detach()
def loss(self, predictions, targets):
"""
Compute BYOL loss.
Arguments:
predictions: Tuple containing `p1` and `p2` (predictions).
targets: Tuple containing `t1` and `t2` (targets).
"""
p1, p2 = predictions
t1, t2 = targets
def byol_loss_fn(x, y):
x = F.normalize(x, dim=-1)
y = F.normalize(y, dim=-1)
return 2 - 2 * (x * y).sum(dim=-1).mean()
loss_1 = byol_loss_fn(p1, t2)
loss_2 = byol_loss_fn(p2, t1)
return loss_1 + loss_2
def update_target_network(self):
"""
Updates the weights of the target network using an EMA of the online network.
"""
for online_params, target_params in zip(self.online_encoder.parameters(), self.target_encoder.parameters()):
target_params.data = self.tau * target_params.data + (1 - self.tau) * online_params.data
def transform(self, image):
"""
Applies BYOL-specific augmentations (e.g., random crops, flips, color jitter).
Returns a function that creates two augmented views of the same image.
"""
augmentation = transforms.Compose([
transforms.RandomResizedCrop(224, scale=(0.2, 1.0)),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(0.4, 0.4, 0.4, 0.1), # Brightness, contrast, saturation, hue
transforms.RandomGrayscale(p=0.2),
transforms.GaussianBlur(kernel_size=3),
transforms.ToTensor(),
transforms.Normalize(mean=(0.5, 0.5, 0.5), std=(0.5, 0.5, 0.5))
])
# Takes an input image and returns two different augmented views.
view1 = augmentation(image)
view2 = augmentation(image)
return view1, view2
Train BYOL
Train a BYOL (Bootstrap Your Own Latent) model using a given dataset and optimizer settings. This process involves iterative training over multiple epochs with stochastic gradient descent, random augmentations for self-supervised learning, and exponential moving average (EMA) updates for the target network.
def train_byol(model, train_loader, num_epochs=10, lr=0.001):
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
for epoch in range(num_epochs):
model.train()
for i, (images, _) in enumerate(train_loader):
images = images.to(device)
# Create two random augmentations (views) per image
image1_list, image2_list = transform_image(images, model)
image1 = torch.stack(image1_list).to(device)
image2 = torch.stack(image2_list).to(device)
# Forward pass
p1, p2, t1, t2 = model(image1, image2)
# Compute BYOL loss
loss = model.loss((p1, p2), (t1, t2)) # Pass predictions and targets as tuples
# Backpropagation and optimization
optimizer.zero_grad()
loss.backward()
optimizer.step()
# Update target network using EMA
model.update_target_network()
if (i + 1) % 100 == 0:
print(f'Epoch [{epoch + 1}/{num_epochs}], Step [{i + 1}/{len(train_loader)}], Loss: {loss.item():.4f}')
def transform_image(images, model):
try:
image1_list = []
image2_list = []
for img in images:
img_pil = transforms.ToPILImage()(img.cpu())
# Call the two_augmentations function here (substituted with transform function)
i1, i2 = model.transform(img_pil)
image1_list.append(i1)
image2_list.append(i2)
return image1_list, image2_list
except Exception as e:
logger.error(f"Error in transform_image: {e}")
Testing and Evaluating Model Performance
entrypoint
Initializes and trains a BYOL (Bootstrap Your Own Latent) model using ResNet18 as
the base encoder. The function sequentially performs the following operations:
- Loads the training data.
- Loads a pre-trained ResNet18 model and extracts its feature layers, excluding the final classifier (FC layer).
- Determines the feature size based on the last convolutional block of ResNet18.
- Initializes the BYOL model using the extracted features and feature size.
- Trains the BYOL model over a specified number of epochs with a given learning rate.
def entrypoint():
train_loader = load_data()
# Load pretrained ResNet18 as the base encoder (excluding the classifier)
resnet = torchvision.models.resnet18(weights=torchvision.models.ResNet18_Weights.DEFAULT)
# Extract the feature layers from ResNet for BYOL
feature_extractor = nn.Sequential(*list(resnet.children())[:-1]) # Remove the FC layer
# Determine the feature size from the last convolutional block of ResNet
feature_size = resnet.fc.in_features
# Initialize BYOL Model
model = BYOL(resnet, feature_extractor, feature_size).to(device)
# Train the BYOL model
train_byol(model, train_loader, num_epochs=10, lr=0.001)
Entrypoint for the script.
The main function which calls the entrypoint function to train the BYOL model serves as the application entry point.
if __name__ == '__main__':
entrypoint()
Evaluating Model Performance
During training, the loss values consistently decreased, suggesting effective model learning. Unlike traditional contrastive learning, BYOL’s loss reduction reflects the alignment of online and target network predictions without explicit negative sample comparisons. This decrease indicates the model successfully learns invariant features by predicting one augmented view from another. The consistent loss reduction, even without contrastive negatives, highlights BYOL’s ability to capture meaningful representations, demonstrating robust feature learning comparable to, or potentially exceeding, contrastive methods in certain scenarios. This success in learning without direct negative samples underscores the potential of BYOL for downstream tasks where labeled data is scarce.
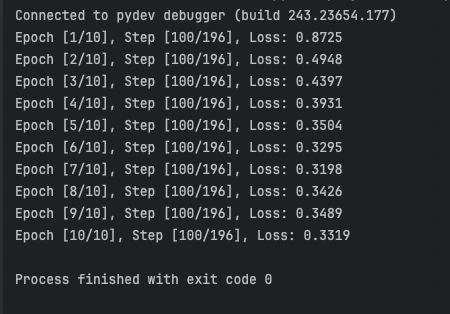
Conclusion
BYOL’s training exhibited a consistent decrease in loss, validating its ability to learn effective representations without negative sampling. This breakthrough has significantly advanced self-supervised learning, showcasing its simplicity, robustness, and strong performance. The ability to achieve such results without contrastive negatives marks a key advancement. As research continues, we can expect further advancements in BYOL and its extensions, leading to even more powerful and efficient representation learning techniques. BYOL’s ability to learn from unlabeled data is vital as the world generates more and more unlabeled information. Its success is a significant stride towards AI models capable of leveraging the vast amounts of unlabeled data, paving the way for more adaptable and intelligent systems.
References
- Bootstrap your own latent: A new approach to self-supervised Learning
- Advanced Deep Learning with TensorFlow 2 and Keras